[오리뎅이의 C 포인터 이야기 - 2] 포인터는 주소다
오리뎅이의 C 포인터 이야기안녕하세요? 오리뎅입니다.

포인터를 위한 기초 체력 증강 프로젝트 그 두번째 시간입니다. 오늘은 첫번째로는 주소의 크기와 더하기 빼기 연산에 대해서 알아 보겠습니다. 두번째는 C언어의 object란 무엇인지에 대해서 알아 봅니다. 그리고 마지막으로 C 언언어의 lvalue와 rvalue에 대해서 알아보면서 포인터를 위한 기초 체력 증강 프로젝트 대 단원의 막(?)을 내리겠습니다. ㅋ
주소의 크기, 그리고 주소의 더하기 빼기
그럼 첫번짹 주제로 주소의 크기와 더하기 빼기 연산에 대해서 알아 보겠습니다. "포인터는 주소다"라고 했으니 주소의 크기와 더하기 빼기는 곧 포인터의 크기와 더하기 빼기와 같습니다. 머래는 것이여? 말이여 방구여? 이럴때는 "백문이 불여일타" 라 했습니다. ^^
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
#include <stdio.h>
typedef struct {
int A;
int B;
int C;
int D;
}structE;
int main (void)
{
char charA; // 1 바이트
short shortB; // 2 바이트
int intC; // 4 바이트
double doubleD; // 8 바이트
structE structE; // 16 바이트
int arrayF[8]; // 32 바이트
printf("\n");
printf("자료형 크기, 포인터(주소) 크기\n");
printf("\n");
printf("sizeof charA = %2ld, sizeof(&charA) = %ld\n", sizeof charA, sizeof(&charA));
printf("sizeof shortB = %2ld, sizeof(&shortB) = %ld\n", sizeof shortB, sizeof(&shortB));
printf("sizeof intC = %2ld, sizeof(&intC) = %ld\n", sizeof intC, sizeof(&intC));
printf("sizeof doubleD = %2ld, sizeof(&doubleD) = %ld\n", sizeof doubleD, sizeof(&doubleD));
printf("sizeof structE = %2ld, sizeof(&structE) = %ld\n", sizeof structE, sizeof(&structE));
printf("sizeof arrayF = %2ld, sizeof(&arrayF) = %ld\n", sizeof arrayF, sizeof(&arrayF));
printf("\n");
printf("포인터(주소) 1 더하기 연산 \n");
printf("\n");
printf("&charA = %p, &charA + 1 = %p\n", &charA, &charA + 1);
printf("&shortB = %p, &shortB + 1 = %p\n", &shortB, &shortB + 1);
printf("&intC = %p, &intC + 1 = %p\n", &intC, &intC + 1);
printf("&doubleD = %p, &doubleD + 1 = %p\n", &doubleD,&doubleD + 1);
printf("&structE = %p, &structE + 1 = %p\n", &structE,&structE + 1);
printf("&arrayF = %p, &arrayF + 1 = %p\n", &arrayF, &arrayF + 1);
printf("\n");
printf("포인터(주소) 10 더하기 연산 \n");
printf("\n");
printf("&charA = %p, &charA + 10 = %p\n", &charA, &charA + 10);
printf("&shortB = %p, &shortB + 10 = %p\n", &shortB, &shortB + 10);
printf("&intC = %p, &intC + 10 = %p\n", &intC, &intC + 10);
printf("&doubleD = %p, &doubleD + 10 = %p\n", &doubleD,&doubleD + 10);
printf("&structE = %p, &structE + 10 = %p\n", &structE,&structE + 10);
printf("&arrayF = %p, &arrayF + 10 = %p\n", &arrayF, &arrayF + 10);
printf("\n");
printf("포인터(주소) 1 빼기 연산 \n");
printf("\n");
printf("&charA = %p, &charA - 1 = %p\n", &charA, &charA - 1);
printf("&shortB = %p, &shortB - 1 = %p\n", &shortB, &shortB - 1);
printf("&intC = %p, &intC - 1 = %p\n", &intC, &intC - 1);
printf("&doubleD = %p, &doubleD - 1 = %p\n", &doubleD, &doubleD - 1);
printf("&structE = %p, &structE - 1 = %p\n", &structE, &structE - 1);
printf("&arrayF = %p, &arrayF - 1 = %p\n", &arrayF, &arrayF - 1);
return 0;
}
|
cs |
참조1. 주소의 크기와 더하기 빼기 연산 예제
주소의 크기와 더하기 빼기 연산이 결과가 어떻게 나오는지 알아 보기 위해서 참조1 예제를 만들어 봤습니다. 참조1의 12 라인부터 17라인까지를 보면, char 타입부터 short, int, double, struct, array까지 1바이트 크기부터 32바이트 크기까지 자료형들을 선언해 놓았습니다. 16 bytes 자료형은 4 bytes 크기의 int 형 멤버 변수를 4개 가지는 struct 변수를 선언했고, 32 bytes 크기의 자료형은 int 형 요소를 8개 가지는 배열 변수를 선언했습니다. 변수들은 모두 main 함수의 내부에 선언이 되어 있습니다. [오리뎅이의 C 포인터 이야기 - 1]을 읽고 오신 분이시라면, 각 변수들이 stack 영역에 배치될 것이라는 것을 "척 보면 앱~니다!".
"척보면 앱~니다"라는 말은 황기순이라는 개그맨이 1980 년대에 "청춘만만세(청춘행진곡)"라는 프로를 통해서 유행시켰던 유행어입니다. 30년도 더 지난 시절의 유행어를 사용하였네요. 공감해 주실 독자분이 과연 있으셨으려나요? ^^
변수 앞에 &(ampersand)를 붙이면 포인터가 된다
참조1에서 23라인과 28라인까지는 각 자료형의 크기를 출력해 보기 위해서 각 자료 타입의 sizeof 연산 결과를 출력함과 동시에 각 자료 타입의 주소(포인터)의 크기를 출력해 보기 위해서 각 변수 앞에 &(ampersand)를 붙여서 sizeof 연산 결과로 출력하였습니다. 변수 앞에 단항 연산자 &를 붙이면, 연산 결과는 변수가 배치되어 있는 메모리의 주소가 됩니다. 첫번째 부분의 출력 결과를 먼저 살펴 보면 참조2와 같습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
root@n1-duck01:~/limcs/c# gcc -o msize.o mem_size.c
root@n1-duck01:~/limcs/c# ./msize.o
자료형 크기, 포인터(주소) 크기
sizeof charA = 1, sizeof(&charA) = 8
sizeof shortB = 2, sizeof(&shortB) = 8
sizeof intC = 4, sizeof(&intC) = 8
sizeof doubleD = 8, sizeof(&doubleD) = 8
sizeof structE = 16, sizeof(&structE) = 8
sizeof arrayF = 32, sizeof(&arrayF) = 8
|
cs |
참조2. 자료형의 크기와 자료형 주소(포인터)의 크기
참조2의 출력 결과에 보여 지듯이 각 자료형 변수의 크기는 알고 있던 그대로 각 자료형 변수의 크기와 동일하게 출력되었습니다. 자료형의 크기는 플랫폼에 따라 다를 수 있기 때문에 "이것이 정답이다"라고는 말할 수 없습니다.
각 자료형 변수의 크기가 1, 2, 4, 8, 16, 32로 각각 서로 다른것에 비해서 각 자료형의 주소(포인터) 크기는 너도 나도 다 동일하게 8입니다. 모든 자료형 변수에 대해서 주소(포인터)의 크기는 모두 같습니다. 단, 플랫폼이 32bits 플랫폼인 경우에는 주소(포인터)의 크기는 4 bytes, 64bits 플랫폼인 경우에는 주소의 크기가 8 bytes입니다. 제 PC는 64bits 플랫폼이기 때문에 주소의 크기가 모두 동일하게 8로 출력 되었습니다.
비록 크기는 모두 같지만, 주소(포인터) 변수의 타입은 모두 다음 참조3과 같이 제각각 다릅니다. * 라는 것은 같지만 그 포인터(주소)에 들어 있는 자료형의 타입이 다르기 때문에 다릅니다.
|
1
2
3
4
5
6
|
&charA : char * 타입
&shortB : short * 타입
&intC : int * 타입
&double : double * 타입
&structE : structE * 타입
&arrayF : int (*)[8] 타입
|
cs |
참조3. 각 자료형 변수 주소(포인터)의 타입
정수형 변수의 1더하기는 정수 1 증가, 주소형 변수의 1 더하기는?
두번째와 세번째 예제의 출력은 각 주소(포인터)의 1 더하기 연산과 10 더하기 연산 결과입니다. 출력 결과를 살펴 보기 전에 주소(포인터)의 연산에 대해서 잠시 알아 보고 가야겠습니다.
- 주소(포인터)의 연산은 정수 더하기와 빼기만 지원됩니다. 곱하기와 나누기 연산은 지원되지 않습니다.
&intC + 1; // OK, 정수 더하기 OK
&intC - 20; // OK, 정수 빼기 OK
&doubleD + 1.5 // NOK, 정수 아님
&charA * 3 // NOK, 곱하기 안됨
&shortB / 2 // NOK, 나누기 안됨
- 주소에 정수 더하기와 빼기만 될 뿐, 주소와 주소의 더하기, 빼기는 지원되지 않습니다.
&intC + 10; // OK, 정수 더하기 OK
&intC + &intC1 // NOK, 주소 + 연산자의 피연산자로는 정수만 가능
- 주소(포인터)의 더하기와 빼기 연산의 결과값은 주소입니다.
자 이제 참조1의 예제 프로그램을 실행하면 어떤 결과가 나올지 예상이 되시죠? 과연 예상하고 계시는 것과 같은 결과가 나오는지 한번 보시죠.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
포인터(주소) 1 더하기 연산
&charA = 0x7ffe9dacb921, &charA + 1 = 0x7ffe9dacb922 // 1 증가
&shortB = 0x7ffe9dacb922, &shortB + 1 = 0x7ffe9dacb924 // 2 증가
&intC = 0x7ffe9dacb924, &intC + 1 = 0x7ffe9dacb928 // 4 증가
&doubleD = 0x7ffe9dacb928, &doubleD + 1 = 0x7ffe9dacb930 // 8 증가
&structE = 0x7ffe9dacb930, &structE + 1 = 0x7ffe9dacb940 // 16 증가
&arrayF = 0x7ffe9dacb940, &arrayF + 1 = 0x7ffe9dacb960 // 32 증가
포인터(주소) 10 더하기 연산
&charA = 0x7ffe9dacb921, &charA + 10 = 0x7ffe9dacb92b // 10 증가, 0x00a
&shortB = 0x7ffe9dacb922, &shortB + 10 = 0x7ffe9dacb936 // 20 증가, 0x014
&intC = 0x7ffe9dacb924, &intC + 10 = 0x7ffe9dacb94c // 40 증가, 0x028
&doubleD = 0x7ffe9dacb928, &doubleD + 10 = 0x7ffe9dacb978 // 80 증가, 0x050
&structE = 0x7ffe9dacb930, &structE + 10 = 0x7ffe9dacb9d0 // 160 증가, 0x0a0
&arrayF = 0x7ffe9dacb940, &arrayF + 10 = 0x7ffe9dacba80 // 320 증가, 0x140
|
cs |
참조4. 주소의 1 더하기 연산 결과 그리고 10 더하기 연산 결과
주소의 1 더하기 연산 결과는 각 자료형의 크기만큼 주소가 증가하였습니다. 즉, 1바이트 크기의 char 자료형 변수의 주소는 1바이트만큼 증가하고, short 자료형 변수의 주소는 2바이트, int 자료형 변수의 주소는 4 바이트, double 자료형 변수의 주소는 8 바이트 증가하였고, structE와 arrayF는 각각 16 바이트와 32바이트가 증가하였습니다. 아래 그림1은 각 자료형의 포인터 1 더하기 연산 시 주소가 얼마씩 증가하는 지를 보여 주고 있습니다.
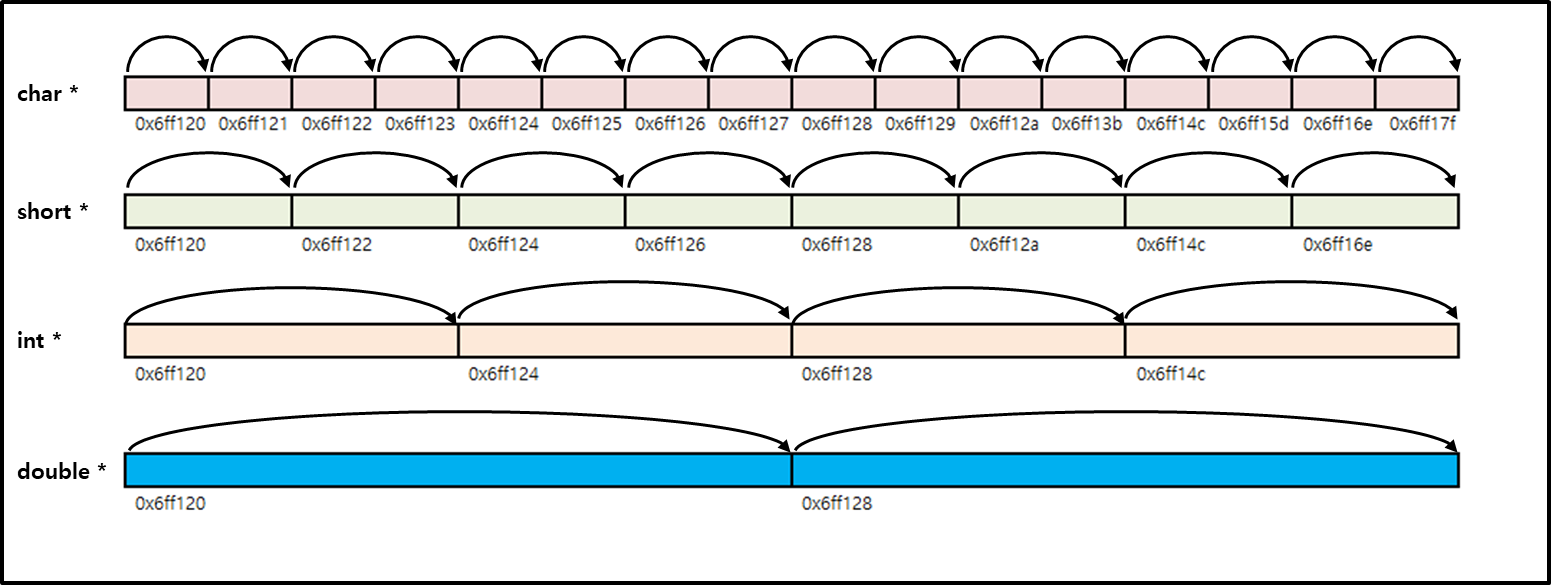
주소의 10 더하기 연산 결과는 1 더하기 연산 결과에 비추어 예상되는 결과와 정확히 일치합니다. char 자료형 변수의 주소는 10 바이트 증가하였고, int 자료형 변수의 주소는 40 바이트가 증가하는 등 정확히 자료형의 크기에 10을 곱한 것만큼 증가한 것을 알 수 있습니다.
1 더하기와 10더하기 연산 출력 결과를 통해서 예상되는 바와 같이 주소(포인터)의 연산은 자료형의 크기가 1 unit 입니다. 주소의 더하기 연산은 (더하기한 숫자 * 자료형의 크기) 만큼 주소가 증가합니다.
주소의 빼기 연산은 어떨까요. 빼기는 당연히 더하기 연산의 반대 결과로 (빼기한 숫자 * 자료형의 크기) 만큼 주소가 감소합니다. 1 빼기 연산 출력 결과를 통해서 실제로 그런 결과가 나왔는지 보시죠!!
|
1
2
3
4
5
6
7
8
9
|
포인터(주소) 1 빼기 연산
&charA = 0x7ffe9dacb921, &charA - 1 = 0x7ffe9dacb920 // 1 감소
&shortB = 0x7ffe9dacb922, &shortB - 1 = 0x7ffe9dacb920 // 2 감소
&intC = 0x7ffe9dacb924, &intC - 1 = 0x7ffe9dacb920 // 4 감소
&doubleD = 0x7ffe9dacb928, &doubleD - 1 = 0x7ffe9dacb920 // 8 감소
&structE = 0x7ffe9dacb930, &structE - 1 = 0x7ffe9dacb920 // 16 감소
&arrayF = 0x7ffe9dacb940, &arrayF - 1 = 0x7ffe9dacb920 // 32 감소
|
cs |
참조5. 주소(포인터)의 1 빼기 연산 결과
참조5의 주소(포인터)의 1 빼기 결과는 참 재미나게도 주소가 모두 동일한 주소(0x7ffe9dacb920)를 출력하고 있습니다. 1 바이트 크기의 char 변수의 주소 1 빼기는 1 바이트가 감소하고, short 변수의 주소 1 빼기는 2 바이트가 감소하고, int 형은 4 바이트 감소, double 형은 8 바이트 감소, structE와 arrayF는 각각 16 바이트, 32 바이트씩 감소한 것을 볼 수 있습니다. 각 자료형의 크기 만큼 감소한 것인데요. 이렇게 더하기와 마찬가지로 주소(포인터)의 정수 빼기 연산은 포인터 변수의 자료형의 크기가 감소 단위(unit)입니다. 이렇게 주소의 정수 빼기 연산을 배우고 난 후에, 주소(포인터)의 정수 빼기를 하면 덜 헷갈리는데요. 주소와 주소간 빼기를 할 때, 이게 좀 혼동되기 쉽습니다. 예를 들면 다음과 같은 경우입니다.
int iArr[4] = {1, 2, 3, 4};
int *piArr0 = &iArr[0]; // piArr0는 배열 iArr의 첫 번째 요소 주소
int *piArr2 = &iArr[2]; // piArr2는 배열 iArr의 두 번째 요소 주소 = 첫 번째 요소 주소 + 8
printf("piArr2 - piArr0 = %d", piArr2 - piArr0); // 출력 결과가 2 가 나오면 "어!! 2가 거기서 왜 나와?" 하게 된다.
참조6. (주소 - 주소)의 결과는 C 입문자의 상습 혼란 유도기
참조6과 같이 주소에서 주소를 빼는 연산의 결과는 주소의 자료형 크기가 unit 1이 되는데, 주소 크기만큼 감소할 것으로 예상해서 혼란에 빠지는 경우가 많습니다. 참조6의 경우 주소로는 int 자료형 크기 4의 2배인 8이 차이가 나므로 빼기 연산에서도 8을 예상했다가, 2가 나오면 "어!! 2가 거기서 왜 나와???" 하고 멘붕에 빠질 수 있습니다.
참조5의 코드 예제에서는 스택 메모리 영역에 각 변수가 배치될 때, 배치된 주소가 절묘하게 1, 2, 4, 8, 16, 32 로 배수로 증가해서 주소의 정수 1 빼기 연산의 결과가 모두 동일한 주소를 가리키는 결과가 나왔습니다. 그림2는 각 자료형의 포인터 1 빼기 연산 시 주소가 얼마씩 감소하는 지를 보여 주고 있습니다.

주소 10 빼기 연산 결과는 왜 없냐구요? ^^ 한번 직접 수정해서 확인해 보세요. 자료형 크기의 곱하기 10을 한 것만큼 주소가 감소하는 것을 직접 확인해 보세요.
C에는 object가 (있다, 없다)
C++이나 자바, 그리고 파이썬에는 class(클래스)가 있습니다. 드라마 제목 "이태원 클라쓰"에 나오는 클라쓰는 클래스의 사투리 버전일까요? ^^ 암튼 그 클라쓰가 클래스이고 영어 표기로는 class로 같습니다. C 언어에는 class가 없습니다. Class가 있고 없고에 따라서 C++, 자바, 그리고 파이썬과 같은 class가 있는 언어들은 객체(object) 지향 언어라고 부르고, class가 없이 함수가 절차(순서)대로 실행되는 C 언어는 절차 지향 언어라고 부릅니다. 그렇습니다. C는 객체(object) 지향 언어는 아닙니다. 그렇지만 C에도 object가 있습니다. 그런데, C에서 object는 class 로 대변되는 객체 지향 언어에서 사용되는 그 객체(object)와는 다른 의미로 사용됩니다. C11 표준에서 object에 대한 정의는 다음과 같습니다.
3.15
1 object
region of data storage in the execution environment, the contents of which can represent values
2 NOTE When referenced, an object may be interpreted as having a particular type; see 6.3.2.1.
출처 : C11 ISO/IEC 9899:201x 표준 문서 3.15
참조6. C의 object에 대한 정의
Object는 C 프로그램 실행 환경의 데이터 저장 영역. 구글 번역기의 해석입니다. [오리뎅이의 C 포인터 이야기 - 1] 편에서 C 프로그래밍 메모리 레이아웃에 대해서 알아 보았었는데요. C 프로그램이 실행되는 환경에서 각종 변수와 상수 등이 메모리의 어느 위치에 배치되는지를 알아 보았었습니다. 메모리에 저장된 변수와 상수의 저장 영역도 object입니다. 영역(region)이라는 말에는 연속된 저장공간 덩어리의 개념이 있습니다. 참조될 수 있는 방법이 있고, 무한 공간이 아닌 크기가 한정된 저장 공간 덩어리가 object입니다. 위에서 참조1의 예제를 이용해 charA, shortB, intC, doubleD, structE, arrayF의 각 변수가 실행환경에서 stack 메모리의 어느 주소에 저장되며, 각각의 변수의 크기는 얼마인지를 알아 보았었습니다. 저희가 확인해 보았던 그 각 변수들의 메모리 영역(주소와 크기)이 C에서 말하는 object입니다. 변수나 상수들만이 object인 것은 아닙니다. C 프로그램 실행 환경에서 데이터의 저장소(storage)는 메모리(RAM) 이외에도 Flash Memory, ROM도 있고, 각종 주변 장치 디바이스들이 자체적으로 가지고 있는 register, buffer, fifo 등의 메모리 공간도 있습니다. 이름, 참조 주소, index 등으로 접근할 수 있고, 크기가 정해져 있으면 object입니다.
C 언어에서 포인터가 전지전능한(?) 이유가 바로 이 모든 종류의 object를 포인터로 접근할 수 있기때문입니다. 각종 디바이스 메모리나 FPGA, ASIC 등의 register에도 address만 연결되면 포인터를 이용해서 디바이스의 메모리나 reginster에 데이터를 쓰거나, 값을 읽어 올 수 있습니다.
object 설명에 대한 NOTE 끝부분에 "6.3.2.1을 참조하십시오." 라고 적혀 있어서 6.3.2.1도 가져와서 구글 번역기를 돌려 보았습니다. 내용이 좀 많은데다가 문장 구조가 좀 복잡해서 구글님 번역만으로는 이해하기가 상당히 난해 했었습니다. 조금씩 의역을 넣어서 수정을 해 보았습니다. 포인터를 잘 이해하기 위해서 아래 번역해 놓은 내용을 모두 이해해야 하는 것은 아닙니다. 그냥 쓱 한번 읽어 보시기만 하고 지나 가시면 됩니다.
6.3.2 Other Operands
6.3.2.1 Lvalues, arrays, and function designators
1 An lvalue is an expression (with an object type other than void) that potentially designates an object;64) if an lvalue does not designate an object when it is evaluated, the behavior is undefined. When an object is said to have a particular type, the type is specified by the lvalue used to designate the object. A modifiable lvalue is an lvalue that does not have array type, does not have an incomplete type, does not have a const qualified type, and if it is a structure or union, does not have any member (including, recursively, any member or element of all contained aggregates or unions) with a const qualified type.
1 lvalue는 잠재적으로 객체(object)를 지정하는 표현식 (void 이외의 객체 유형)입니다 .64) lvalue가 평가(evaluation) 될 때 객체(object)를 지정하고 있지 않으면 정의되지 않은 동작(undefined behavior)입니다. 객체(object)가 특정 유형(type)을 갖는다 고 할 때 유형(type)은 객체(object)를 지정하는 데 사용되는 lvalue에 의해 지정됩니다. 수정 가능한 lvalue는 배열 type이 아니고 불완전한 type(크기가 정해지지 않은 배열)이 아니고, const 한정된 type이 아니고, 구조체 또는 공용체 경우에는 const로 한정된 멤버를 가지지 않습니다
2 Except when it is the operand of the sizeof operator, the unary & operator, the ++ operator, the -- operator, or the left operand of the . operator or an assignment operator, an lvalue that does not have array type is converted to the value stored in the designated object (and is no longer an lvalue); this is called lvalue conversion.
If the lvalue has qualified type, the value has the unqualified version of the type of the lvalue; additionally, if the lvalue has atomic type, the value has the non-atomic version of the type of the lvalue; otherwise, the value has the type of the lvalue.
If the lvalue has an incomplete type and does not have array type, the behavior is undefined. If the lvalue designates an object of automatic storage duration that could have been declared with the register storage class (never had its address taken), and that object is uninitialized (not declared with an initializer and no assignment to it has been performed prior to use), the behavior is undefined.
2 sizeof 연산자의 피연산자, 단항 & 연산자의 피연산자, ++ 연산자의 피연산자, --연산자의 피연산자 또는 . 연산자 또는 할당(=, += 등) 연산자의 좌항 피연산자를 제외하고, 배열 type이 아닌 lvalue는 지정된 객체(object)에 저장된 값으로 변환되며 더 이상 lvalue가 아닙니다. 이것을 lvalue 변환(lvalue conversion)이라고합니다.
lvalue가 한정된 type을 가지면(int const * ptr) vlaue는 lvalue type의 한정되지 않은 버전을 갖습니다. 또한, lvalue가 atomic type을 갖는 경우(int _Atomic *ptr) 값은 lvalue type의 non atomic 버전을 갖습니다. 그렇지 않으면 값은 lvalue의 type을 갖습니다. lvalue에 불완전한 type(int arr[])이 있고 배열 유형이 없으면 정의되지 않은 동작입니다.
lvalue가 레지스터 스토리지 클래스로 선언 될 수있는 자동 저장 기간의 객체를 지정하고 (그 주소를 사용하지 않은 경우) 해당 객체가 초기화되지 않은 경우 (이니셜 라이저로 선언되지 않고 사용 전에 할당되지 않은 경우) ), 동작이 정의되지 않았습니다.
3 Except when it is the operand of the sizeof operator or the unary & operator, or is a string literal used to initialize an array, an expression that has type ‘‘array of type’’ is converted to an expression with type ‘‘pointer to type’’ that points to the initial element of the array object and is not an lvalue. If the array object has register storage class, the behavior is undefined.
sizeof 연산자 또는 단항 & 연산자의 피연산자 이거나 배열을 초기화하는 데 사용되는 문자열 리터럴 인 경우를 제외하고, "array of type'' type을 가진 표현식은 배열 객체(object)의 첫번째 요소를 가리키는 ''pointer to type" 의 type을 가진 표현식으로 변환(conversion)되고, lvalue가 아닙니다. 배열 객체가 레지스터 스토리지 클래스를 가지면 동작이 정의되지 않습니다.
4 A function designator is an expression that has function type. Except when it is the operand of the sizeof operator65) or the unary & operator, a function designator with type ‘‘function returning type’’ is converted to an expression that has type ‘‘pointer to function returning type’’.
4 함수 지정자(함수 이름)는 함수 type을 가지는 표현식입니다. sizeof 연산자 65) 또는 단항 & 연산자의 피연산자 인 경우를 제외하고‘‘ type을 반환하는 함수’’ type의 함수 포인터는 ‘‘type을 반환하는 함수에 대한 pointer’’ type을 가지는 표현식으로 변환됩니다.
64) The name ‘‘lvalue’’ comes originally from the assignment expression E1 = E2, in which the left operand E1 is required to be a (modifiable) lvalue. It is perhaps better considered as representing an object ‘‘locator value’’. What is sometimes called ‘‘rvalue’’ is in this International Standard described as the ‘‘value of an expression’’.
An obvious example of an lvalue is an identifier of an object. As a further example, if E is a unary expression that is a pointer to an object, *E is an lvalue that designates the object to which E points.
64) 이름‘‘lvalue’’는 원래 할당 표현식 E1 = E2에서 유래되었으며, 여기서 왼쪽 피연산자 E1은 (수정 가능한) lvalue 여야합니다. 아마도 객체(object) '‘로케이터 값 : 위치를 찾아내는 값’’을 나타내는 것으로 간주하는 것이 좋습니다. 때때로‘‘rvalue’’라고 하는 것은‘‘표현식의 값:value of an expression’’으로 설명되는 국제 표준에 있습니다.
lvalue의 명백한 예는 객체(object)의 식별자(변수 이름)입니다. 추가적인 예로 어떤 객체(object)에 대한 포인터인 E가 단항 표현식에 있는 경우, *E는 E가 가리키는 객체(object)를 지정하는 lvalue입니다
65) Because this conversion does not occur, the operand of the sizeof operator remains a function designator and violates the constraint in 6.5.3.4.
65) 이 변환이 발생하지 않기 때문에 sizeof 연산자의 피연산자는 함수 지정자로 남아 6.5.3.4의 제약 조건을 위반합니다.
출처 : C11 ISO/IEC 9899:201x 표준 문서 6.3.2.1
참조2. 피연산자 lvalues, arrays 그리고 function designators
lvalue vs rvalue
C11 표준의 6.3.2.1 항의 주석 64)에 lvalue와 rvalue에 대한 설명이 나옵니다. E1 = E2에서 유래 되었다고 설명하고, 왼쪽 피연산자 E1은 (수정 가능한) lvalue 여야 한다고 설명하고 있습니다. 객체(object)의 위치를 찾아내는 값(locator value)으로 간주하는게 좋겠다고 설명합니다. 결정적으로 밑부분에 "lvalue의 명백한 예는 객체(object)의 식별자(변수 이름)입니다.". 변수 이름 자체가 명백한 lvalue의 예라고 하는군요. 6.3.2.1의 2항 부분을 보면, lvalue가 아니라 lvalue가 가리키는 객체(object)에 저장된 value로 변환되는 lvalue conversion에 대해서 설명하고 있습니다. 2항 앞 부분에 lvalue 변환이 일어나지 않는 예외 경우들에 대해서 열거하고 있습니다. 이해를 돕기 위해서 예제를 포함하여 아래에 다시 열거해 보았습니다.
- sizeof 연산자의 피연산자
printf("%d", sizeof intC); // siozeof 피연산자 intC는 lvalue 유지
- 단항 & 연산자의 피연산자
printf("%p", &intC); // & 피연산자 intC는 lvalue 유지
- ++ 연산자의 피연산자
++intC; // 전위 연산자 ++ 피연산자 intC는 lvalue 유지
shortB++; // 후위 연산자 ++ 피연산자 shortB는 lvalue 유지
- --연산자의 피연산자
--intC; // 전위 연산자 -- 피연산자 intC는 lvalue 유지
shortB--; // 후위 연산자 -- 피연산자 shortB는 lvalue 유지
- . 연산자의 좌항 피연산자
structE.A = 100; // 구조체 변수의 멤버 면수 접근 연산자 . 의 좌항 구조체 변수는 lvalue 유지
- 할당 연산자(=, += 등)의 좌항 피연산자
intC = 10; // 대입 연산자의 좌항 피연산자 intC는 lvalue 유지
- 배열 type
printf("%p", arrayE); // int arrayE[8] arrayE는 lvalue 유지
참조3. lvalue conversion이 일어 나지 않는 경우의 예
위에 언급된 것들과 다르게 사용되는 lvalue object는 lvalue conversion이 되서 object에 저장된 value로 변환된다는 것인데요. 정말 그런지 간단한 예를 들어서 확인해 보겠습니다.
int intC, intC1 = 10, intC2 = 20;
intC = intC1 + intC2; // intC는 = 연산자 좌항 피연산자이므로 lvalue 유지
// intC1, intC2는 lvalue conversion 되어, value 10과 20이 됨
printf("%d, %d, %d", intC,intC1,intC2); // intC, intC1, intC2 모두 lvalue conversion 되어 30,10,20이 됨
참조3을 몇번 보고 고개를 끄덕 끄덕 하고 나면, object의 식별자가 lvalue로 사용되는 경우와 lvalue conversion이 되어 value로 사용되는 경우를 어렵지 않게 구분할 수 있을 것 같습니다. ^^
*E는 E가 가리키는 객체(object)를 지정하는 lvalue다
참조2에서 주석 64)의 붉은색 부분은 포인터의 정체성에 대해서 설명해 주고 있습니다. 이 부분이 포인터를 이해하기 쉽고, 해석하기 쉽게 해 줄 key point 인 것 같습니다. *E에서 E자신도 pointer 객체(object)의 lvalue이고, *E도 E가 가리키는 객체(object)의 lvalue입니다. int *E의 포인터 변수를 선언하는 순간, 2개의 객체(object)와 2개의 lvalue가 선언된 것입니다. 이중 포인터로 확장해서 생각해 보면, int **E의 이중 포인터 변수를 선언하는 순간, 3개의 객체와 3개의 lvalue가 선언된 것입니다. E는 포인터 객체이고, *E도 E가 가리키는 포인터 객체이고, **E는 *E가 가리키는 int 객체입니다. 다중 포인터로 확장해도 이것은 마찬가지입니다. int *****E와 같이 선언한다면 별(*)이 5개이니 포인터 객체가 5개이고, int 객체가 1개로 6개의 객체가 선언된 것입니다. 변수를 초기화 하지 않고 사용하면 안되듯이, 포인터 변수 선언 시 선언된 모든 객체는 초기화를 하고 사용해야 합니다.
int *E; // pointer to int : pointer object 1개와 int object 1개
int **E; // pointer to pointer to int : pointer object 2개와 int object 1개
int ***E; // pointer to pointer to pointer to int : pointer object 3개와 int object 1개
int ****E; // pointer to pointer to pointer to pointer to int : pointer object 4개와 int object 1개
int *****E; // pointer to pointer to pointer to pointer to pointer to int : pointer object 5개와 int object 1개
변수가 lvalue로 사용되는 경우와 lvalue coversion이 일어나는 것과 같이 pointer 객체들도 동일하게 lvalue 입니다. lvalue 자리에서는 lvalue로 사용되고 lvalue conversion이 일어나는 곳에서는 value로 사용됩니다. * 하나 하나를 객체 하나로 count 하는 것이 포인터를 쉽게 이해하는 신의 한수입니다. 포인터 변수를 선언하면 포인터 변수가 가리키는 객체들도 초기화가 되어야만 문제 없이 사용될 수 있습니다. 따라서 다중 포인터가 선언되더라도 *에 해당하는 객체가 어느 것인지를 아는 것은 어렵지 않게 파악할 수 있습니다. 아래의 예를 한번 보시죠.
int D1 = 10, D2;
int *E1 = &D1, *E2; // int *E1, *E2는 pointer object와 int object 도합 2개 object
int **F1 = &E1, **F2 = &E2; // int **F1, **F2는 pointer object 2개와 int object 도합 3개 object
D2 = D1 + 20; // D2는 lvalue, D1은 lvalue conversion 되어 value 10으로 사용됨
E2 = &D2; // E2는 lvalue, D2도 & 연산자의 피연산자로 lvalue로 사용됨
*E1 = *E2; // *E1 (= D1)은 lvalue, *E2(=D2)는 lvalue conversion 되어 value 30으로 사용됨
**F1 = **F2; // 3개 object 중에서 3번째 int object가 **F1은 lvalue, **F2는 value로 사용됨
*F1 = *F2; // 3개 object 중에서 2번째 pointer object *F1는 lvalue, *F2은 value로 사용됨.
위의 예에서 E1은 선언되면서 &D1으로 초기화 되었습니다. E1의 type은 int * (pointer to int)이고, *E의 type은 int입니다. 2개의 object가 선언되고, E1은 &D1으로 초기화 되고, *E1(=D1)은 위에서 10으로 각각 초기화 되었습니다. 이 것이 사용될 때에 E1으로 사용되면 첫번째 객체의 lvalue이고, *E1으로 사용되면 두번째 객체(D1)의 lvalue라는 것을 "척 보면 앱~~니다.". 이중 포인터로 선언된 F1과 F2도 마찬가지입니다. 3개의 object가 선언되었고, F1과 F2는 첫번째 local stack에 선언된 pointer objec입니다. **F1, **F2는 세번째 object인 D1과 D2의 lvalue입니다. 어느 position에 사용되느냐에 따라서 lvaue로 사용되거나, lvalue conversion이 일어나서 세번째 object의 value로 사용될 수도 있습니다. *F1과 *F2는 각각 두번째 object인 E1과 E2의 lvalue라는 것을 알수 있습니다.
이상으로 포인터를 공부하기 위한 기초체력 증강 프로젝트를 모두 마치겠습니다. ^^ 지난 이야기와 이번 회차의 이야기는 깊이 있게 파고 들어 완전히 이해하려고 하면 꽤나 어려운 내용일 수 있습니다. 쭈웈 읽으시면서 여기까지 오셨으면 더 뒤돌아 보지 않으셔도 됩니다. 다음 글에서 본격적으로 포인터 이야기 시작해 보겠습니다.
뼈때리는 지적의 댓글도, 힘내라 북돋아 주는 격려의 댓글도, 좀 더 디테일을 원하거나 관련된 지식에 대해 질문을 하거나 하는 댓글도 너무 너무 환영합니데이~~~ 댓글 달아 주이~~~~소!!
2021년 1월 12일 수원에서 뒤뚱뒤뚱~~~~ [오리]

'오리뎅이의 C 포인터 이야기' 카테고리의 다른 글
| [오리뎅이의 C 포인터 이야기 - 5] 배열의 포인터 변환 (4) | 2021.01.30 |
|---|---|
| [오리뎅이의 C 포인터 이야기 - 4] 포인터의 영원한 동반자 배열 (1) | 2021.01.24 |
| [오리뎅이의 C 포인터 이야기 - 3] 오리뎅이 포인터 학습법 (2) | 2021.01.17 |
| [오리뎅이의 C 포인터 이야기 - 1] 포인터를 쉽게 배울수 있을까요? (3) | 2021.01.09 |