[오리뎅이의 C 포인터 이야기 - 5] 배열의 포인터 변환
오리뎅이의 C 포인터 이야기안녕하세요? 오리뎅이입니다.

사진은 제가 인도 뭄바이에 주재원으로 있을 때, 패밀리 회원권을 끊어서 주말마다 가던 BPGC(Bombay Presidency Golf Club)의 클럽 하우스 바로 앞에 있는 야외 풀장 모습입니다. 사진을 보고 있자니, 저 골프장에 주말마다 갔었으면서도 정작 저 풀장은 한번도 들어가 본 적은 없었네요. 뜨거운 열사의 나라 사우디 리야드 골프 코스(RGC)에서 골프를 배우고, 만만치 않게 덮고 습한 인도 뭄바이에서 골프를 즐겼었지만, 정작 한국에 돌아와서는 골프채를 1년에 한번 잡을까 말까하네요. 골프장이 몇 개 없어서 부킹도 어렵던 나라에서는 열심히 골프를 즐겼는데, 동네 방네 발길에 채이는 게 골프장인 한국에서는 골프보다 재미난 놀거리가 많아서인지 안땡겨요. ^^

포인터와 함께 C 학습을 어렵게 하는 또 하나의 암초같은 존재가 배열입니다. 배열이 처음 배울 때 어려운 이유는 바로 오늘 학습하게 될 배열이 포인터로 변환되는 특성때문입니다. 그런데 어렵게 느껴지게 만드는 배열의 포인터 변환 특성만 정확히 알고 있으면 배열도 포인터와 마찬가지로 딱 보면 척 알 수 있습니다. ^^
배열과 포인터
[오리뎅이의 C 포인터 이야기 - 2] 편에서 C 언어의 object(객체)를 설명하기 위해서 인용했었던 "C11 ISO/IEC 9899:201x 표준 문서6.3.2.1"에는 다음과 같이 array와 관련된 부분이 있습니다.
3 Except when it is the operand of the sizeof operator or the unary & operator, or is a string literal used to initialize an array, an expression that has type ‘‘array of type’’ is converted to an expression with type ‘‘pointer to type’’ that points to the initial element of the array object and is not an lvalue. If the array object has register storage class, the behavior is undefined.
sizeof 연산자 또는 단항 & 연산자의 피연산자 이거나 배열을 초기화하는 데 사용되는 문자열 리터럴 인 경우를 제외하고, "array of type'' type을 가진 표현식은 배열 객체(object)의 첫 번째 요소를 가리키는 "pointer to type" type을 가진 표현식으로 변환(conversion)되고, lvalue가 아니다. 배열 객체가 레지스터 스토리지 클래스를 가지면, 정의되지 않은 동작입니다.
출처: C11 ISO/IEC 9899:201x 표준 문서 6.3.2.1절 3항
참조1. C11 표준 6.3.2.1절 3항 내용
딱 3가지 경우를 제외하고, '"array of type" type을 가진 표현식은 배열 객체(object)의 첫 번째 요소를 가리키는 "pointer to type"의 type을 가진 표현식으로 변환(conversion)되며, lvalue가 아니다' 라고 설명하고 있습니다. 다음의 배열이 포인터로 변환되지 않는, 즉 제외되는 딱 3가지 경우의 예입니다.
int iArr[2]; // array [3] of int1. sizeof 의 피연산자
printf("%d", sizeof (iArr));
2. 단항 &(ampersand) 연산자의 피연산자printf("%p", &iArr);
3. 배열을 초기화하는 데 사용되는 문자열 리터럴
char cArr[12] = "Hello world"; // 문자열 리터럴 "Hello world"은 'array [12] of char' 타입이고,
// char 배열 변수를 초기화 하는데 사용될 때는 배열 그 자체로 사용
참조2. 배열이 pointer로 변환 되지 않는 딱 3가지 경우
참조2에 기술한 딱 3가지 경우에는 배열은 pointer로 conversion이 일어나지 않고, 배열 그 자체로 사용되는 경우입니다. 배열이 참조2의 딱 3가지 경우로 사용되지 않을 때에는 배열의 첫 번째 요소를 가리키는 pointer로 conversion 됩니다.
배열이 pointer로 변환 되는 경우에도 법칙이 있다
배열과 포인터는 배우 닮았습니다. 배열 인덱스 연산자, [ ]는 식별자의 우측에 포인터 참조 연산자 *는 식별자의 좌측에 위치해서 마치 식별자를 기준으로 거울을 마주 보고 있는듯한 느낌입니다. 포인터와 관련된 배열의 특징들을 나열해 보면 다음과 같습니다.
-, 배열은 그 배열의 첫번째 요소를 가리키는 포인터로 변환 된다.
N차원의 다차원 배열은 그 배열의 첫 번째 요소인 N-1차원 배열 포인터로 변환된다.
-, 배열의 연산자 [] 하나는 포인터 연산자 * 하나와 서로 매칭된다.
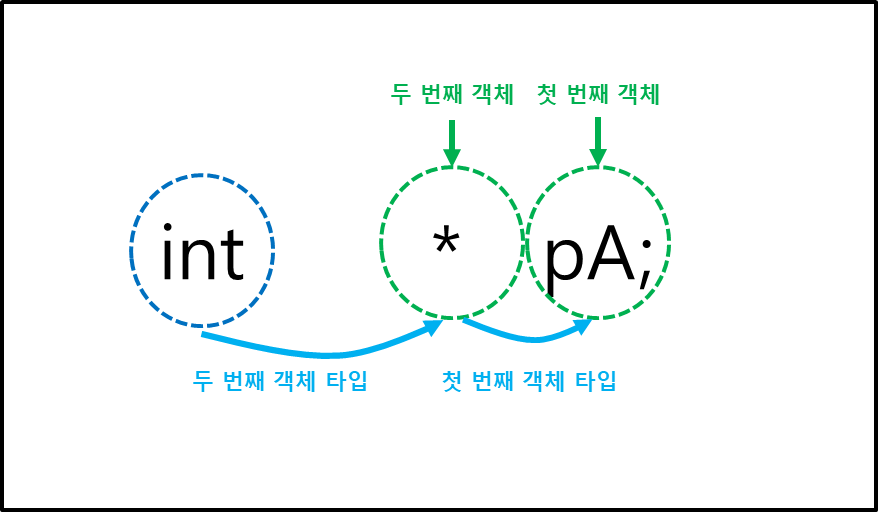
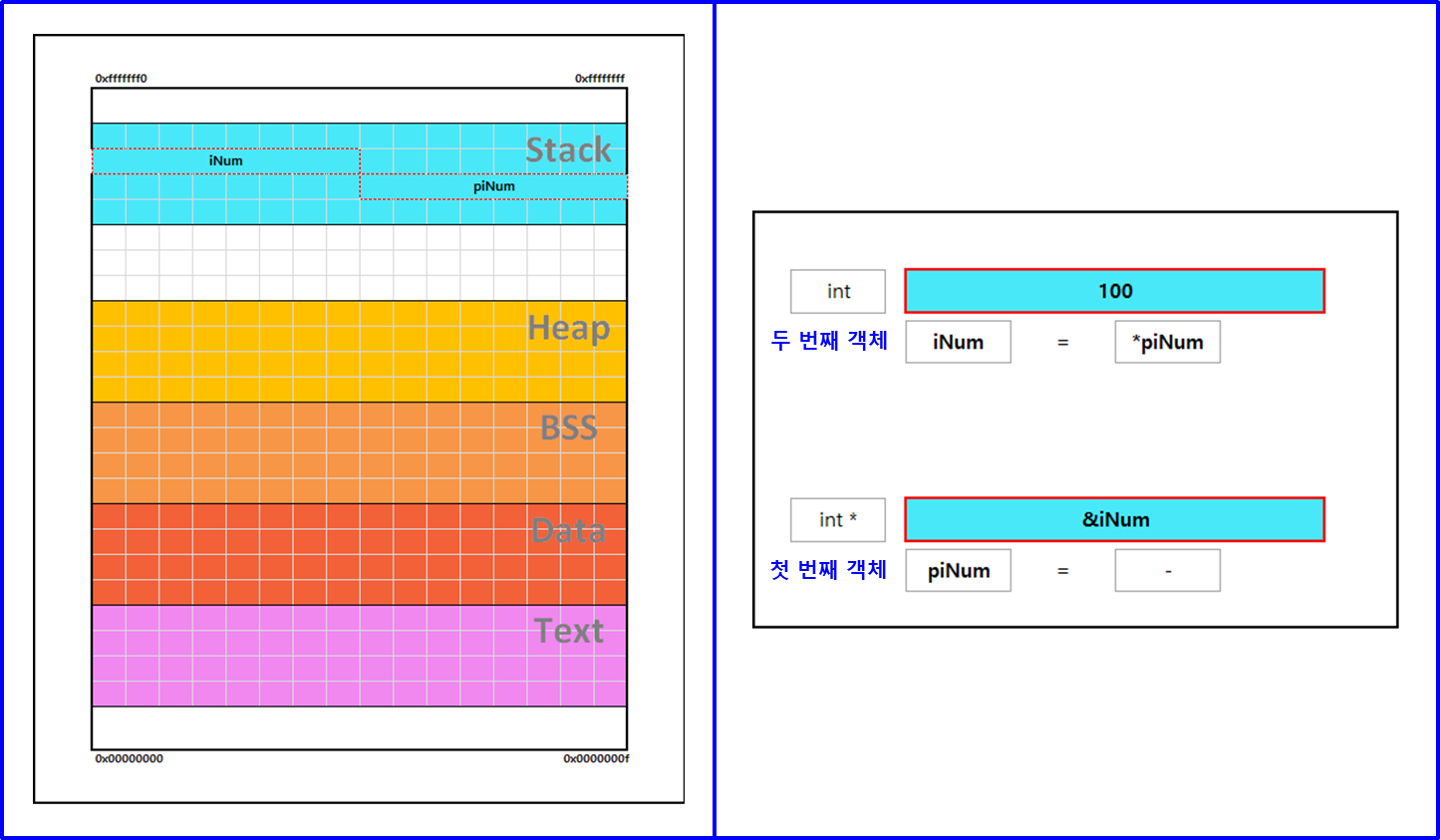
int *iPtr; // iPtr은 첫번째 객체로 포인터 type, *iPtr 은 두 번째 객체 int type
int aArr[2]; // aArr은 배열 객체 그자체 int [2] 배열, *aArr은 배열의 첫 번째 요소 객체 aArr[0]
-, 배열은 lvalue가 아니다.
1차원 배열의 요소만이 lvalue이다.
배열 p가 2차원 배열이면, *p는 1차원 배열이고, 배열이므로 lvalue가 아니다.
배열 p가 2차원 배열이면, **p는 1차원 배열의 요소이고, lvalue이다.
배열 p가 3차원 배열이면, *p는 2차원 배열이고, 배열이므로 lvalue가 아니다.
배열 p가 3차원 배열이면, **p는 1차원 배열이고, 배열이므로 lvalue가 아니다.
배열 p가 3차원 배열이면, ***p는 1차원 배열의 요소이고, lvalue이다.
배열은 lvalue가 아니므로 대입 연산의 좌항 피연산자로 사용될 수 없다.
배열은 lvalue가 아니므로 lvalue conversion 되어 value로 사용될 수 없다.
참조3. 배열의 포인터 변환 관련 특징들
배열의 포인터 관련 특징 중 핵심은 붉은색 굵은 글씨체로 마킹한 2가지입니다. 참조2의 딱 3가지 경우를 제외한 경우에 배열이 그 배열의 첫 번째 요소를 가리키는 포인터로 변환되는 것이 이번 이야기에서 계속해서 강조하고 있는 배열의 첫 번째 특징입니다. 두 번째 특징은 배열이 lvalue가 아니라는 것입니다. lvalue가 아니기 때문에 배열은 대입 연산자의 좌항 피연산자가 될 수 없습니다. 또한, 어느 위치에 사용되건 lvaue conversion이 되어 value로 사용될 수도 없습니다.
3차원 배열은 첫 번째 요소의 포인터로 변환 된다.
3차원 배열을 사용하여 배열의 포인터 변환 관련 특징들을 도식화하여 좀 더 알기 쉽게 알아 보겠습니다.

1. iaaaArr[2][2][2] 은 3차원 배열입니다.
. 영어로 타입을 표현해 보면 다음과 같습니다
- array of [2] array of [2] array of [2] int // array가 3번 나오고, 마지막에 한번만 int 가 나옵니다.
2. iaaaArr 이 &와 sizeof의 피연산자로 사용되면, pointer conversion 되지 않습니다.
. &iaaaArr // 그림1에서 가장 바깥쪽 네모 박스 ①을 가리키는 포인터(주소)입니다.
// &iaaaArr + 1 의 더하기 연산을 하면, ①의 크기 32만큼 주소가 증가
. sizeof(iaaaArr) // 그림1에서 가장 바깥쪽 네모 박스 ①의 크기 32를 나타냅니다
3. iaaaArr이 &와 sizeof 피연산자가 아닌 용도로 사용되면, 첫 번째 요소의 포인터로 변환됩니다.
. int (*piaaArr)[2][2] = iaaaArr; // iaaaArr은 그림1에서 파란색 네모 박스 ②를 가리키는 포인터입니다.
// 첫 번째 요소를 가리키는 &iaaaArr[0] 로 변환됩니다.
// 포인터로 변환 되지만 expression의 결과 값인 rvalue입니다.
4. *iaaaArr은 2차원 배열입니다.
. &*iaaaArr // 그림1에서 파란색 네모 박스 ②를 가리키는 포인터(주소)입니다.
// &*iaaaArr + 1 의 더하기 연산을 하면, ②의 크기 16만큼 주소가
// 증가하여, ⑤ 의 포인터가 됩니다.
. sizeof (*iaaaArr) // 그림1에서 파란색 네모 박스 ②의 크기 16을 나타냅니다.
. int (*piaArr)[2] = *iaaaArr; // 참조 연산자 *를 붙이면, 두 번째 배열 객체 ②가 됩니다.
// iaaaArr[0] 도 2차원 배열이므로, &와 sizeof의 피연산자가 아니면 다시
// 첫 번째 요소를 가리키는 &iaaaArr[0][0]로 변환됩니다.
// 포인터로 변환 되지만 expression의 결과 값인 rvalue입니다.
5. **iaaaArr은 1차원 배열입니다.
. &**iaaaArr // 그림1에서 빨간색 네모 박스 ③를 가리키는 포인터(주소)입니다.
// &**iaaArr + 1 의 더하기 연산을 하면, ③의 크기 8만큼 주소가
// 증가하여, ⑥의 포인터가 됩니다.
. sizeof (**iaaaArr) // 그림1에서 빨간색 네모 박스 ③의 크기 8을 나타냅니다.
. int *piArr = **iaaaArr; // 참조 연산자 *를 2개 붙이면, 세 번째 배열 객체 ③이 됩니다.
// iaaaArr[0][0]도 1차원 배열이므로, &와 sizeof의 피연산자가 아니면
// 첫 번째 요소를 가리키는 &iaaaArr[0][0][0]로 변환됩니다.
// 포인터로 변환 되지만 expression의 결과 값인 rvalue입니다.
6. ***iaaaArr은 1차원 배열의 첫 번째 요소입니다.
. &***iaaaArr // 그림1에서 검정색 네모 박스 ④를 가리키는 포인터(주소)입니다.
// &***iaaArr + 1 의 더하기 연산을 하면, ④의 크기 4만큼 주소가 증가
. sizeof (***iaaaArr) // 그림1에서 검정색 네모 박스 ④의 크기 4를 나타냅니다.
. int iArr = ***iaaaArr; // 참조 연산자 *를 3개 붙이면, 네 번째 int 객체 ④, 즉, 0이 됩니다.
// 3차원 배열에 *을 3개 붙이면, 1차원 배열 요소이고, lvalue입니다.
3차원 배열은 3차원 포인터마냥 참조 연산자 *를 3개 붙이니 최종 1차원 배열의 요소 객체, lvalue가 되었습니다.
그림1에서 ①, ②, ③, ④ 의 4가지 주소는 크기는 다 다르지만, 시작 위치가 같으므로 모두 같은 주소입니다.
①=&iaaaArr,②=iaaaArr(=&iaaaArr[0]),③=iaaaArr[0](=&iaaaArr[0][0]),④=iaaaArr[0][0](=&iaaaArr[0][0][0])
처음 배울 때, ①,②,③,④의 4가지 주소를 출력했는데, 모두 동일한 주소가 나오면, 눈이 땡그래집니다. "오잉!! 왜 다 같게 나오지?" ㅎㅎㅎ. 이제는 눈 땡그래지지 않습니다.
1차원 배열은 첫 번째 요소를 가리키는 단일 포인터로 변환된다.
3차원 배열로 알아 본 내용을 1차원 배열과 2차원 배열의 설명과 코드 예제로 복습해 보겠습니다.

sizeof 연산자의 피연산자 그리고 단항 연산자 &의 피연산자로 배열이 사용될 때, 배열은 배열 그 자체로 사용됩니다. 그림2의 1차원 배열에서 sizeof (iaArr)의 결과는 붉은색 curly bracket, { } 이 나타내는 배열 전체의 크기입니다. &iaArr의 결과도 { } 이 나타내는 배열 전체 크기의 객체(object) 대한 pointer 입니다. iaArr이 sizeof의 피연산자 또는 단항 연산자 &의 피연산자가 아닌 경우에는 iaArr은 그림1에서 배열의 첫 번째 요소, iaArr[0], 즉, 정수 1을 담고 있는 객체를 가르키는 int 형 단일 포인터로 변환됩니다. 배열이 포인터로 변환되더라도 포인터를 저장할 수 있는 메모리 공간을 가진 변수가 아닌 단지 주소를 나타내는 rvalue입니다. 즉, 배열이 포인터로 변환되는 경우 포인터 변수가 아닌 포인터 상수로 변환됩니다. 따라서, 대입연산자의 좌항 피연산자로 사용될 수 없고, iaArr++ 이나 --iaArr과 같은 포인터 자체를 증감하는 연산도 불가능합니다.
1차원 배열의 예제 코드입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
#include <stdio.h>
int main(void)
{
int iArr[2] = {0, 1}; // iArr은 array of [2] int
int *piArr; // piArr은 pointer to int
piArr = iArr; // iArr = &iArr[0], 첫 번째 요소를 가리키는 단일 포인터로 변환
// 1차원 배열 요소는 lvaue이므로 *iArr은 lvalue
*iArr = 10; // 대입 연산자의 좌항 피연산자로 사용가능, *iArr = iArr[0] = 10
*piArr = *iArr + 1; // lvalue conversion, *iArr = iArr[0] = 10
// piArr = iArr 이므로 iArr[0] = 11
*(iArr + 1) = 20; // 포인터의 더하기 연산, *(iArr + 1) = iArr[1] = 20
// 대입 연산의 좌항 피연산자는 1차원 배열만 가능
printf("iArr[0] = %d, iArr[1] = %d\n", iArr[0], iArr[1]);
return 0;
}
-------------------------------------------------------------------------------------------------
iArr[0] = 11, iArr[1] = 20
|
cs |
참조4. 1차원 배열의 포인터 변환 특징
2차원 배열은 첫 번째 1차원 배열 요소 포인터로 변환 된다.
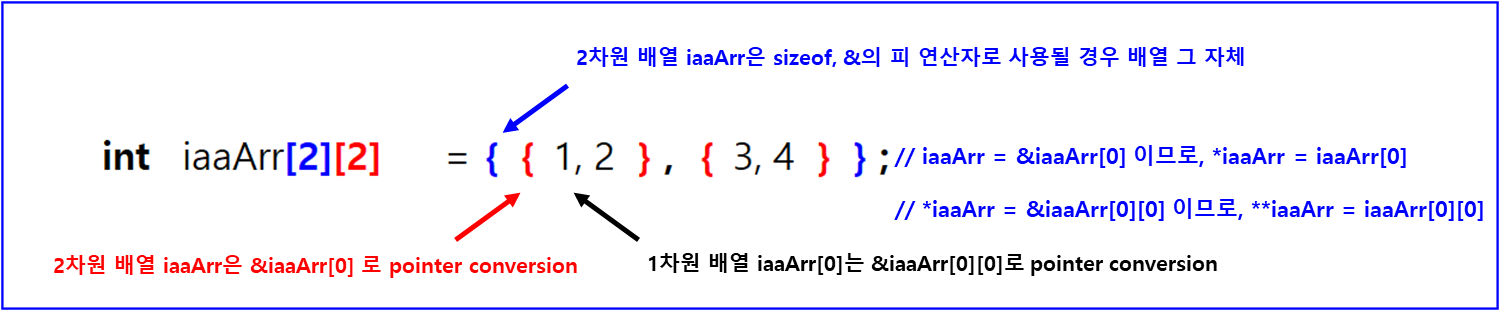
그림3의 2차원 배열에서 sizeof (iaaArr)의 결과는 파란색 curly bracket, { } 이 나타내는 배열 전체의 크기입니다. &iaaArr의 결과도 { } 이 나타내는 배열 전체 크기의 객체(object) 대한 pointer 입니다. 그렇기 때문에 &iaaArr + 1의 더하기 연산 결과는 배열 전체 크기 16 bytes 만큼 증가한 주소가 됩니다. iaaArr이 sizeof의 피연산자 또는 단항 연산자 &의 피연산자가 아닌 경우에는 iaaArr은 그림2에서 붉은색 curly bracket, { 1, 2 } 을 가리키는 첫 번째 요소인 1차원 배열의 포인터로 변환됩니다. 포인터 참조 연산자가 붙으면, *iaaArr은 1차원 배열 {1, 2}, 그 자체입니다. sizeof나 & 연산자로 사용되면, 역시나 1차원 배열 그 자체를 나타내지만, 그 이외의 경우에는 다시 포인터 변환이 일어나서 1차원 배열의 첫 번째 요소를 가리키는 포인터로 변환되고, **iaaArr은 iaaArr[0][0]으로 숫자 1이 저장된 int 객체를 나타내는 lvalue 입니다.
2차원 배열의 예제 코드입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
#include <stdio.h>
int main(void)
{
int iaaArr[2][3] = {0, 1, 2, 3, 4 }; // array of [2] array of [3] int
int (*paiArr)[3]; // pointer to array of [3] int
int *piArr0, *piArr1;
paiArr = iaaArr; // 이차원 배열은 1차원 배열 포인터로 변환
printf("&iaaArr = %p, sizeof(iaaArr) = %d, iaaArr = %p\n",
&iaaArr, sizeof(iaaArr), iaaArr);
printf("&*iaaArr = %p, sizeof(*iaaArr) = %d, *iaaArr = %p\n",
&*iaaArr, sizeof(*iaaArr), *iaaArr);
printf("&**iaaArr = %p, sizeof(**iaaArr) = %d, **iaaArr = %d\n",
&**iaaArr, sizeof(**iaaArr), **iaaArr);
printf("\n");
piArr0 = iaaArr[0]; // 1차원 배열은 단일 포인터로 변환
printf("&iaaArr[0] = %p, sizeof(iaaArr[0]) = %d, iaaArr[0] = %p\n",
&iaaArr[0], sizeof(iaaArr[0]), iaaArr[0]);
printf("**iaaArr = %d, *iaaArr[0] = %d, iaaArr[0][0] = %d\n",
**iaaArr, *iaaArr[0], iaaArr[0][0]); // 0
printf("*(*iaaArr+1) = %d, *(iaaArr[0]+1) = %d, iaaArr[0][1] = %d\n",
*(*iaaArr+1), *(iaaArr[0]+1), iaaArr[0][1]); // 1
printf("\n");
piArr1 = iaaArr[1]; // 1차원 배열은 단일 포인터로 변환
printf("&iaaArr[1] = %p, sizeof(iaaArr[1]) = %d, iaaArr[1] = %p\n",
&iaaArr[1], sizeof(iaaArr[1]), iaaArr[1]);
printf("**(iaaArr+1) = %d, *iaaArr[1] = %d, iaaArr[1][0] = %d\n",
**(iaaArr+1), *iaaArr[1], iaaArr[1][0]); // 3
printf("*(*(iaaArr+1)+1) = %d, *(iaaArr[1]+1) = %d, iaaArr[1][1] = %d\n",
*(*(iaaArr+1)+1), *(iaaArr[1]+1), iaaArr[1][1]); // 4
return 0;
}
-------------------------------------------------------------------------------------------------
&iaaArr = 000000000062FDF0, sizeof(iaaArr) = 24, iaaArr = 000000000062FDF0
&*iaaArr = 000000000062FDF0, sizeof(*iaaArr) = 12, *iaaArr = 000000000062FDF0
&**iaaArr = 000000000062FDF0, sizeof(**iaaArr) = 4, **iaaArr = 0
&iaaArr[0] = 000000000062FDF0, sizeof(iaaArr[0]) = 12, iaaArr[0] = 000000000062FDF0
**iaaArr = 0, *iaaArr[0] = 0, iaaArr[0][0] = 0
*(*iaaArr+1) = 1, *(iaaArr[0]+1) = 1, iaaArr[0][1] = 1
&iaaArr[1] = 000000000062FDFC, sizeof(iaaArr[1]) = 12, iaaArr[1] = 000000000062FDFC
**(iaaArr+1) = 3, *iaaArr[1] = 3, iaaArr[1][0] = 3
*(*(iaaArr+1)+1) = 4, *(iaaArr[1]+1) = 4, iaaArr[1][1] = 4
|
cs |
참조5. 2차원 배열의 포인터 변환 특징
참조5의 코드를 카피해서 본인의 로컬 머신에서 직접 컴파일하고, 실행하셔서 코드 행간 내용과 출력 결과를 비교해 보세요.
2차원 배열 iaaArr[2][3]는 int 형 요소 3개를 가진 1차원 배열 2개를 가진 2차원 배열입니다. 크기는 2 x 3 x 4 = 24입니다. 1차원 배열은 int 형 요소 3개이므로 크기가 3 x 4 = 12입니다. int 자료형의 크기는 제 PC에서는 4이군요. 11 ~ 16 라인에서 주소와 크기를 축력해 본 결과가 43 ~ 45 라인에 있습니다. 주소는 모두 동일하게 나옵니다. 크기는 각각 다릅니다.
33 ~ 34 라인에서 iaaArr+1 의 포인터 더하기 연산을 하였습니다. 그랬더니, 1차원 배열의 크기 12만큼 주소가 증가해서 두 번째 1차원 배열을 가리키는 포인터가 되었습니다. 2차원 배열에 * 을 2개 붙이니 1차원 배열 첫 번째 요소가 되고, lvalue conversion이 되어 3이 출력 되었습니다.

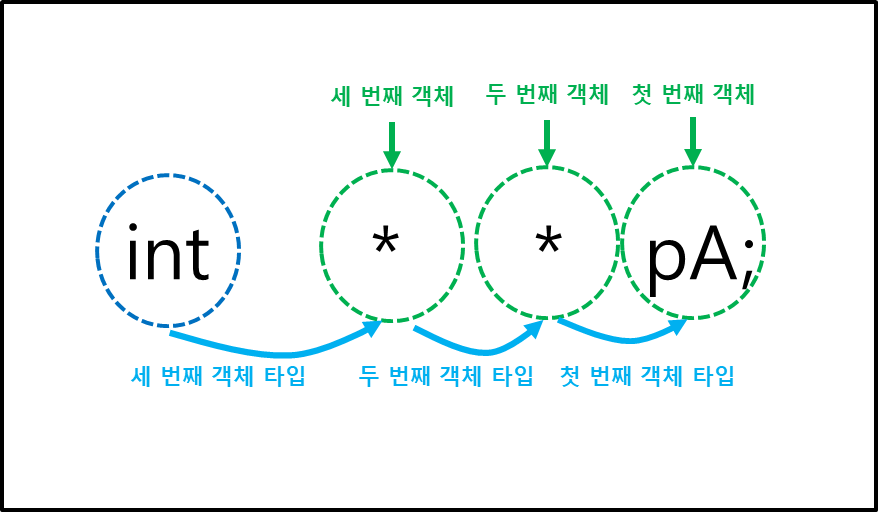
인자 배열의 포인터 변환 껌이쥬? ^^. 아래 5중 포인터와 5차원 배열의 극한 비교를 쓱 보시면 배열의 포인터 변호나 쌉 정리 가능!!

-, 배열은 그 배열의 첫번째 요소를 가리키는 포인터로 변환 된다.
-, 배열은 lvalue가 아니다.
1차원 배열의 요소만이 lvalue이다.
C에서 배열은 함수의 매개 변수가 될 수 없다
배열이 C를 공부하는 나를 혼란스럽게 하는 또 한가지 경우가 배열처럼 생긴 모양으로 함수의 매개 변수로 사용되는 포인터 경우입니다. 분명한 것은 C에서는 배열을 함수 인자로 전달할 수 없습니다. 배열 처럼 생긴 함수의 매개 변수는 배열의 탈을 쓴 포인터입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
#include <stdio.h>
int SummaryArray(int piArr[], int iCnt) // piArr은 배열의 탈을 쓴 포인터
{ // int piArr[] = int *piArr
int i, iSum = 0;
for (i = 0; i < iCnt; i++)
{
iSum += piArr[i];
}
return iSum;
}
int main()
{
int iArr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int iSum = 0;
iSum = SummaryArray(iArr, sizeof(iArr) / sizeof(int)); // iArr = &iArr[0], 포인터 변환
printf("Sum = %d\n", iSum);
return 0;
}
-------------------------------------------------------------------------------------------------
Sum = 55
|
cs |
참조6. 함수의 매개 변수로 사용 된 배열의 탈을 쓴 포인터
참조6의 예에서 라의 3의 SummaryArray 함수의 매개 변수로 사용된 int piArr[]은 생김새로만 봐서는 영락 없는 배열의 모습니다. 그러나 바뜨, 이거슨 배일이 아닙니다. 포인터입니다. C에서 배열 자체를 함수의 인자로 전달하는 것을 지원하지 않습니다. C가 함수의 인자 evaluation strategy가 모조리 값을 copy해서 넘기는 call by value만 지원하는 관계로 배열 변수도 값을 copy해서 넘긴다면, 엄청난 크기의 배열을 요소 하나 하나 copy해서 넘기는 건 좀 성능상 아닐 것 같아서 인 것도 같고요. 배열은 lvaue가 아니라서 배열 자체가 대입 연산자의 좌항 피연산자로 사용될 수도 없으니, 값을 copy 한다는 것도 대입의 일종으로 본다면 안되는 게 맞는거 같기도 합니다. 아뭏튼 어째튼 저째튼 C에서는 배열을 함수의 매개 변수로 사용할 수 없습니다. 대신에 뭔 수작인지 몰라도 저런 배열의 탈을 쓴 포인터 문법을 허용합니다. 생김새는 배열처럼 생겨 먹었지만, 포인터라는 것을 기억하기만 하면 한나도 안 어렵습니다.
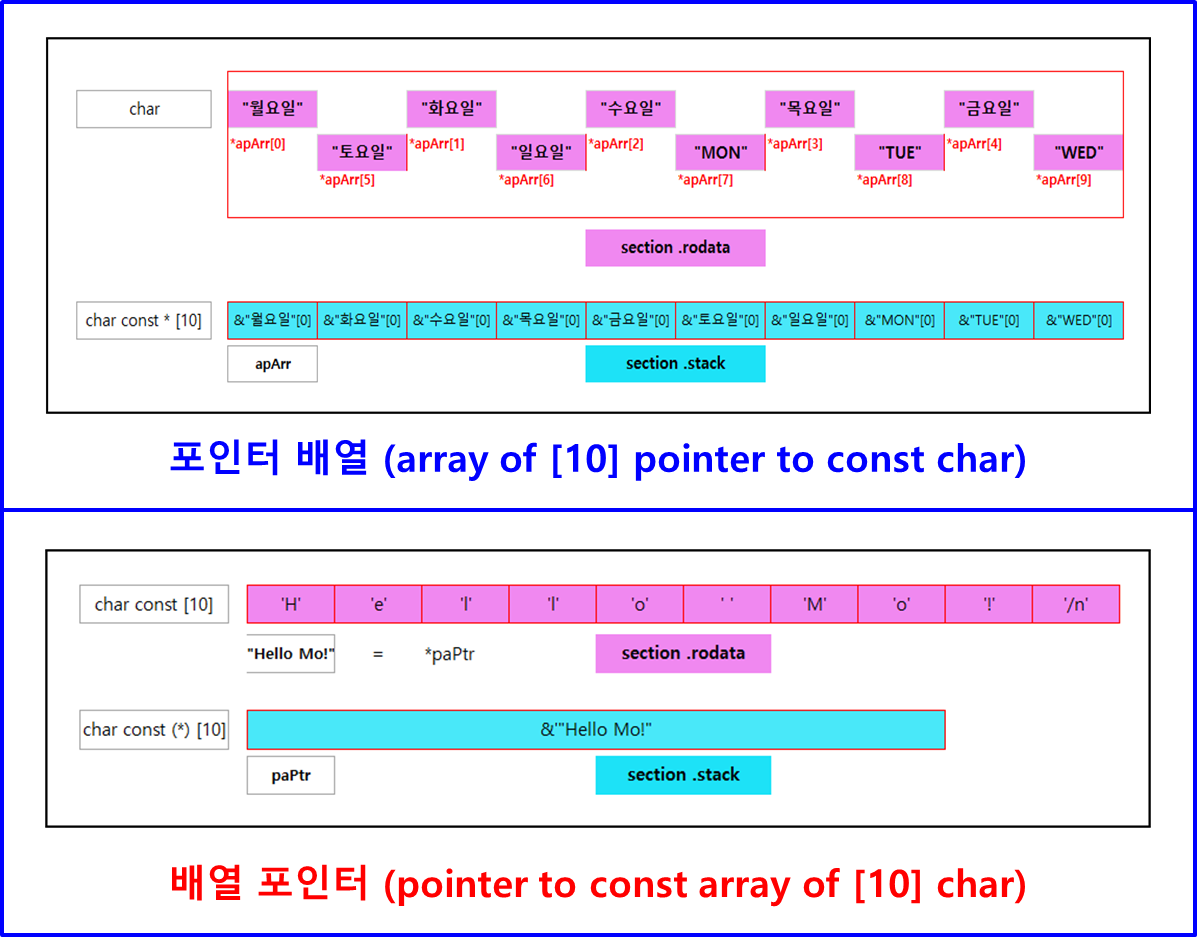
[오리뎅이의 C 포인터 이야기 - 4] 에서 포인터 배열과 배열 포인터의 차이를 알아 보았었고, 배열 포인터 만드는 방법도 확인해 보았었습니다. 기억을 되새김질해 보기 위해서 참조 자료를 소환합니다.
char const *apArr[10]; // 이 것은 포인터 배열인가? 배열 포인터인가? : [정답] 포인터 배열입니다.
// 식별자 apArr과 [] 사이에 괄호가 없으면 배열
char const (*paPtr)[10]; // 이 것은 포인터 배열인가? 배열 포인터인가? : [정답] 배열 포인터입니다.
// 식별자 paPtr 앞에 *가 있고, 이 것들을 ()가 감싸고 있으면 포인터
함수의 매개 변수로 사용하는 다차원 배열의 모습을 한 인자도 역시나 배열의 탈을 쓴 포인터입니다. "이 머선 말이고?" ^^ 아래의 예제 코드를 통해서 머선 말인지 한번 확인해 보시죠.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
#include <stdio.h>
void ArraySwap(int piaArr[][5], int iaCnt) // piaArr은 배열의 탈을 쓴 포인터
{ // int piaArr[][5] = int (*piaArr)[5]
int iTemp[5], i;
for (i = 0; i < 5; i++)
{
iTemp[i]= piaArr[0][i];
piaArr[0][i] = piaArr[1][i];
piaArr[1][i] = iTemp[i];
}
printf("sizeof (piaArr) = %2d, sizeof (*piaArr) = %2d\n",
sizeof (piaArr), sizeof (*piaArr));
}
int main()
{
int iaArr[2][5] = { {1, 2, 3, 4, 5}, {6, 7, 8, 9, 10} };
int i, j;
printf(":: Before ArraySwap()\n");
for (i = 0; i < 2; i++)
{
for (j = 0; j < 5; j++)
{
printf("%2d ", iaArr[i][j]);
}
printf("\n");
}
ArraySwap(iaArr, sizeof(iaArr) / ((sizeof(int) * 5))); // iArr = &iaArr[0], 포인터 변환
printf("\n:: After ArraySwap()\n");
for (i = 0; i < 2; i++)
{
for (j = 0; j < 5; j++)
{
printf("%2d ", iaArr[i][j]);
}
printf("\n");
}
return 0;
}
-------------------------------------------------------------------------------------------------
:: Before ArraySwap()
1 2 3 4 5
6 7 8 9 10
sizeof (piaArr) = 8, sizeof (*piaArr) = 20
:: After ArraySwap()
6 7 8 9 10
1 2 3 4 5
|
cs |
참조7. 2차원 배열의 탈을 쓴 배열 포인터
참조 7의 예제 코드에서 ArraySwap() 함수의 매개 변수인 int piaaArr[][5] 은 생긴 것은 딱 2차원 배열의 모습을 하고 있습니다. 배열인 것 같지만, 겉모양에 속으면 안됩니다. ^^. C는 배열을 함수의 인자로 넘기지 못합니다. 함수 매개 변수에 배열처럼 생긴 것이 있으면, 1차원 배열 모양이건 3차원 배열 모양이건 무조건 포인터입니다.

배열이 은제는 포인터로 변환되고 은제는 아니되는지 딱 보믄 알것지라~이? ^^. C 포인터 이야기 끝이 보이네요. 다음 이야기에서는 또 하나의 복병 함수 포인터에 대해서 신박한 예제들을 가지고 썰을 풀어 볼 예정입니다. 함수 포인터만 이야기 하면, 공부할 주제들은 다 끝난 것이어요. 오늘도 끝까지 [오리뎅이 C 포인터 이야기]를 읽어 주셔서 고맙습니다.
뼈때리는 지적의 댓글도, 힘내라 북돋아 주는 격려의 댓글도, 좀 더 디테일을 원하거나 관련된 지식에 대해 질문을 하거나 하는 댓글도 너무 너무 환영합니데이~~~ 댓글 달아 주이~~~~소!!
2021년 1월 30일 수원에서 [오리뎅이]
'오리뎅이의 C 포인터 이야기' 카테고리의 다른 글
| [오리뎅이의 C 포인터 이야기 - 4] 포인터의 영원한 동반자 배열 (1) | 2021.01.24 |
|---|---|
| [오리뎅이의 C 포인터 이야기 - 3] 오리뎅이 포인터 학습법 (2) | 2021.01.17 |
| [오리뎅이의 C 포인터 이야기 - 2] 포인터는 주소다 (1) | 2021.01.12 |
| [오리뎅이의 C 포인터 이야기 - 1] 포인터를 쉽게 배울수 있을까요? (2) | 2021.01.09 |